I thought it would be fun to test a variety of open source LLMs on actual client work using Codex cli.
I created a benchmark test based on real client requests in existing codebases, then sorted the tasks from easiest to hardest.
The results were surprising. I found that coding benchmarks don’t necessarily line up with my real work. The smarter models often got lost in a train of thought and didn’t actually edit the files.
A model that can solve a standalone programming problem is not always useful when the task is “fix this small client issue in a five-year-old WordPress theme without making a mess.”
If you plan to do a similar test using Codex cli and DeepInfra, you might need a shim to connect the two.
Summary of Results
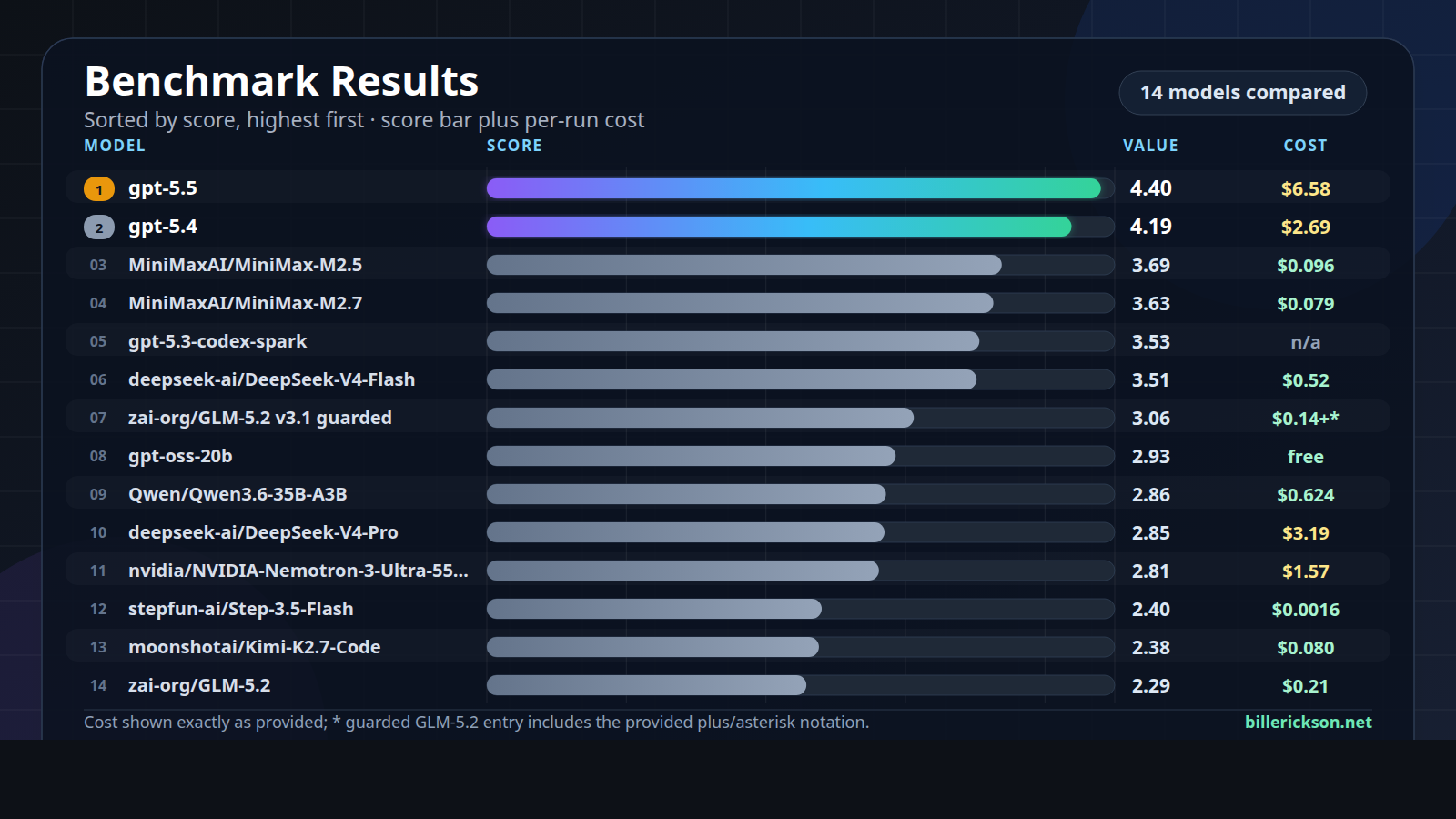
The top OpenAI models won on quality. That was not surprising. I’m sure the Anthropic models would also be towards the top, but I wanted to compare my daily driver (gpt-5.5) to open source models.
MiniMax was the biggest price/performance surprise, which led me to do a second benchmark test comparing just those two models.
GLM-5.2’s poor performance was also unexpected. You can see the Test Details below for more details on its run.
The “cost” column shows the actual cost of running this test on DeepInfra based on the token usage. The OpenAI costs are based on their API pricing, but I’m on one of their paid plans which drastically subsidizes token usage.
I used a free local model (gpt-oss-20b) as a baseline benchmark, and didn’t expect it to score in the middle of the pack on these tasks.
MiniMax Test
Given the surprising results for the MiniMax models, and how close their scores were in the first test, I created a new benchmark test with six new tasks just to test those two models. All these tasks were medium-to-hard, so the scores are lower.
MiniMax-M2.7 averaged 2.63 across the 6 tasks and spent $0.146. It was cheaper on tokens, but it failed three precision tasks badly.
MiniMax-M2.5 averaged 3.53 across the 6 tasks and spend $0.150. It was slightly more expensive, but materially more reliable on PHP/WordPress tasks.
Summary: I’m going to keep using gpt-5.5 as my primary model, but I might try using MiniMax-M2.5 for simpler tasks.
Test Details
This benchmark tested coding-agent behavior across four WordPress theme tasks using short, natural prompts while starting Codex in the correct theme directory with the CultivateWP standard profile active. Task 1 was a read-only brand-color lookup, Task 2 was a mechanical migration of custom ACF block manifests from apiVersion 2 to 3, Task 3 was a focused footer email/form link styling fix, and Task 4 was a broader post-header implementation. Scores are out of 5 per task, with the average reflecting the four-task run where available.
The clearest pattern was that lookup and mechanical edits were much easier than design-aware implementation. Several models could find `theme.json` or update 23 `block.json` files cleanly, but struggled once the task required choosing the right SCSS/PHP source target, preserving build parity, and stopping with a small reviewable diff.
zai-org/GLM-5.2
GLM-5.2 averaged 2.29 at an estimated cost of $0.21. It handled the brand-color lookup well after the benchmark metadata issue was corrected, but the implementation tasks exposed a persistent stall pattern. Task 2 produced some clean, narrow manifest edits but did not finish the full set, and Tasks 3 and 4 ended without meaningful implementation before operator caps.
The result was a model that could understand the repo and identify relevant areas, but did not reliably cross from inspection into completed changes. In this benchmark, that made it weak as a hands-off coding agent despite a solid read-only task result.
After the initial poor results, we made some process changes and re-ran the test, which you’ll find below in zai-org/GLM-5.2 v3.1 guarded.
moonshotai/Kimi-K2.7-Code
Kimi-K2.7-Code averaged 2.38 at an estimated cost of $0.080. It answered the brand-color lookup accurately, but was slow for such a simple read-only task and did extra searching after finding the authoritative file. On the coding tasks, it repeatedly found the right files or target sets, then stalled without producing a usable diff before caps were reached.
This made Kimi one of the more frustrating runs: the exploration often looked promising, but the final worktree did not reflect that understanding. Its low estimated cost helps, but the lack of completed edits on Tasks 2-4 makes it hard to trust for unattended implementation.
stepfun-ai/Step-3.5-Flash
Step-3.5-Flash averaged 2.40, with cost recorded as at least $0.0016 because some interrupted tasks did not emit final usage. It was fast and accurate on the brand-color lookup, but Task 2 showed serious scope-control problems. Although it changed the API version, it also removed acf.mode, added customClassName broadly, reformatted files, and kept wandering after the useful part of the edit was done.
Task 3 found helpful context but produced no diff, and Task 4 was skipped after the reduced task set showed below-threshold implementation behavior. The tiny cost is interesting, but the edits were not reviewable enough for real production use.
nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B
Nemotron Ultra averaged 2.81 at an estimated cost of $1.57. It did well on the first two tasks: the lookup was accurate, and the ACF block API migration produced a strong final diff. However, those wins came with high token use and some malformed validation commands on the mechanical edit.
The implementation side was the problem. Task 3 did not land a source fix and left behind a backup artifact. Task 4 was skipped for budget protection, so the overall result was a strong start followed by an expensive implementation failure.
deepseek-ai/DeepSeek-V4-Pro
DeepSeek-V4-Pro averaged 2.85 at an estimated cost of $3.19. Its first two tasks were excellent from a final-diff perspective: accurate lookup, clean mechanical manifest updates, and good validation shape. The downside was efficiency, especially Task 2, which took about four minutes and nearly 0.9M input tokens for a straightforward file-wide version bump.
Task 3 ran for more than 11 minutes without producing a diff, and Task 4 was not run. The model appeared to be reasoning toward a plausible source target, but for this benchmark the scored deliverable was the finished worktree, not the direction of travel. The cost-to-output ratio was poor.
Qwen/Qwen3.6-35B-A3B
Qwen3.6-35B-A3B averaged 2.86 at an estimated cost of $0.624. It completed the lookup correctly and did make real edits on Tasks 2 and 3, but those edits were not especially disciplined. Task 2 finished the migration but introduced unnecessary support and context changes, making the diff riskier than the clean one-line manifest updates from stronger runs.
Task 3 produced a plausible local CSS change, but likely targeted the narrower block CSS path instead of the intended footer form output. It also burned more than 2M input tokens on that scoped styling task. Task 4 was effectively a no-op on the actual worktree, which kept the overall score below the stronger partial implementers.
gpt-oss-20b
The local gpt-oss-20b averaged 2.93 and was free to run locally. It remained a useful baseline: accurate on the brand-color lookup, clean on the mechanical block.json migration, and much better behaved than several paid hosted models on artifact hygiene. It avoided backup files and did not dump compiled CSS during the footer exploration.
Its weakness was implementation follow-through. Task 3 identified relevant block files but never edited CSS or SCSS, and Task 4 returned almost immediately with no useful work. The model was cheap and tidy, but not capable enough for the two realistic coding tasks in this benchmark.
zai-org/GLM-5.2 v3.1 guarded
The guarded GLM-5.2 rerun averaged 3.06, with cost recorded as at least $0.14. The neutral guardrail materially improved the mechanical ACF block task: Task 2 went from incomplete in the original GLM run to a clean, correct migration. That suggests GLM’s failures were partly sensitive to task framing and agent-loop behavior, not just inability to understand the repo.
The guardrail did not fix broader implementation reliability. Tasks 3 and 4 still burned time on inspection and ended without useful diffs before operator caps. It was a meaningful improvement over the original GLM run, but not enough to make it competitive with the better implementation performers.
deepseek-ai/DeepSeek-V4-Flash
DeepSeek-V4-Flash averaged 3.51 at an estimated cost of $0.52. It was strong on the lookup and mechanical API migration, producing scoped, valid changes. Compared with V4-Pro, it was cheaper and ultimately more useful in this benchmark because it completed all four tasks and produced real implementation diffs.
The implementation quality was still only partial. Task 3 was syntactically clean but likely missed the intended footer form link target, and included a risky truncate-and-recover episode. Task 4 refreshed visible post-header styling with source and compiled CSS, but missed deeper template and recipe-card compatibility behavior expected by the golden path.
gpt-5.3-codex-spark
gpt-5.3-codex-spark averaged 3.53; cost was marked n/a because no official API price was available. It performed well on the lookup and mechanical manifest update, with a clean final diff on Task 2 despite some failed shell attempts and an inaccurate final file count. As with many models, the simple tasks were much stronger than the implementation tasks.
Task 3 attempted the right area but produced brittle styling work: malformed source SCSS, hand-appended compiled CSS, and a link color that likely failed the readability goal in the dark footer. Task 4 produced valid PHP and some useful conditional behavior, but skipped source SCSS and broader recipe-template compatibility. It was a real coding run, just not a clean one.
MiniMaxAI/MiniMax-M2.7
MiniMax-M2.7 averaged 3.63 at an estimated cost of $0.079. It was one of the strongest price/performance results in the benchmark. The lookup was accurate and very fast, and Task 2 produced a correct final migration with clean validation, though it initially missed the nested manifest before recovering.
The implementation tasks were real but partial. Task 3 made a plausible local block CSS fix, but probably missed the actual footer form path. Task 4 improved PHP structure and source SCSS more cleanly than M2.5, but did not update compiled CSS or address the broader WPRM/template compatibility expected by the reference implementation. For the cost, it was impressive; for production use, it still needed careful review.
MiniMaxAI/MiniMax-M2.5
MiniMax-M2.5 averaged 3.69 at an estimated cost of $0.096. It was the biggest pleasant surprise of the DeepInfra set. The model was accurate on the lookup, produced an exactly correct API-version diff on Task 2, and generally delivered useful edits at low cost.
Its weaker side was implementation precision. Task 3 produced a diff instead of stalling, but likely targeted the wrong footer form source path and dumped a large compiled CSS file into the transcript. Task 4 touched PHP, source SCSS, and compiled CSS, but missed major golden-path behavior around metadata helpers and WPRM recipe-template compatibility, and validation left some artifact concerns.
gpt-5.4
GPT-5.4 averaged 4.19 at an estimated cost of $2.69. It was strong across the first two tasks, including a sourced brand-color answer and an exact, well-scoped ACF block API edit. It spent more tokens than necessary on the simple migration, but the final work was correct and reviewable.
Its implementation tasks were meaningfully better than the open-model field, though still not perfect. Task 3 likely fixed the front-end readability issue, but did so with a new enqueued stylesheet and broader WPForms targeting than the reference. Task 4 delivered valid PHP and runtime CSS, but missed several golden touch points.
gpt-5.5
GPT-5.5 was the top performer, averaging 4.40 at an estimated cost of $6.58. It was accurate and well sourced on the lookup, produced the expected tracked diff for the ACF block API migration, and avoided backup artifacts. It was not perfectly efficient, but the final outputs were consistently more useful than the rest of the field.
The most important difference was that GPT-5.5 produced the strongest implementation results. Task 3 was functional, scoped, accessibility-conscious, and kept source SCSS and compiled CSS in sync. Task 4 was a genuine hard-task implementation with focused files, clean PHP syntax, compiled front-end CSS, and reasonable use of existing helpers. It still missed parts of the historical golden direction, but it was the best practical coding-agent result in the benchmark.
Leave A Reply